
人工智障瞎学
人工智障瞎学
一、环境配置
1 | tensorflow-gup==2.0 |
tensorflow2.0 解决pycharm自动补全与应用bug(reference csy)
注: 修改里我们仅仅修改了keras的import路径,所以keras需要使用from tensorflow import keras; 而import keras中其他的包例如layers,需要写成from tensorflow.python.keras import xxxx;
Go to the dir /python3/site-packages/ and change the name of /tensorflow/ to /tensorflow_back/, then change the name of /tensorflow_core/ to /tensorflow/
Go to the file /tensorflow/init.py(which was in /tensorflow_core/), add following codes:
1 | from .python.keras.api._v2 import keras |
二、基本概念
1、监督学习与无监督学习
机器学习中,可以根据学习任务的不同,分为监督学习(Supervised Learning),无监督学习(Unsupervised Learning)、半监督学习(Semi-Supervised Learning)和强化学习(Reinforcement Learning).
监督学习:就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现分类的目的,也就具有了对未知数据进行分类的能力。监督学习中的数据中是提前做好了分类的信息的,如垃圾邮件检测中,他的训练样本是提前存在分类的信息,也就是对垃圾邮件和非垃圾邮件的标记信息
监督学习中,他的训练样本中是同时包含有特征和标签信息的,
监督学习中,比较典型的问题就是像上面说的分类问题(Classfication)和回归问题(Regression)
它们两者最主要的特点就是分类算法中的标签是离散的值,就像上面说的邮件分类问题中的标签为{1, -1},分别表示了垃圾邮件和非垃圾邮件
而回归算法中的标签值一般是连续的值,如预测一个人的年龄,一般要根据身高、性别、体重等标签,这是因为年龄是连续的正整数
无监督学习:是另一种常用的机器学习算法,它与监督学习的不同之处,在于我们事先没有任何训练样本,而需要直接对数据进行建模,无监督学习的样本是不包含标签信息的,只有一定的特征,所以由于没有标签信息,学习过程中并不知道分类结果是否正确。
2、线性回归、逻辑回归
回归问题的条件/前提:
1) 收集的数据
2) 假设的模型,即一个函数,这个函数里含有未知的参数,通过学习,可以估计出参数。然后利用这个模型去预测/分类新的数据。
最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
数据的熵:K-L散度源于信息论。信息论主要研究如何量化数据中的信息。
熵的主要作用是告诉我们最优编码信息方案的理论下界(存储空间),以及度量数据的信息量的一种方式。理解了熵,我们就知道有多少信息蕴含在数据之中,现在我们就可以计算当我们用一个带参数的概率分布来近似替代原始数据分布的时候,到底损失了多少信息。
熵的本质是香农信息量的期望。现有关于样本集的2个概率分布p和q,其中p为真实分布,q非真实分布,H(p,q)我们称之为“交叉熵”。
交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
信息熵代表的是随机变量或整个系统的不确定性,熵越大,随机变量或系统的不确定性就越大。
根据真实分布,我们能够找到一个最优策略,以最小的代价消除系统的不确定性,而这个代价大小就是信息熵,记住,信息熵衡量了系统的不确定性,而我们要消除这个不确定性,所要付出的【最小努力】(猜题次数、编码长度等)的大小就是信息熵。
梯度下降:
批量梯度下降法(Batch Gradient Descent, BGD):是梯度下降法的最原始形式,每迭代一步或更新每一参数时,都要用到训练集中的所有样本数据,当样本数目很多时,训练过程会很慢。
随机梯度下降法(Stochastic Gradient Descent, SGD):由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。随机梯度下降法正是为了解决批量梯度下降法这一弊端而提出的。随机梯度下降是通过每个样本来迭代更新一次。SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着最优化方向进行。
小批量梯度下降法(Mini-Batch Gradient Descent, MBGD):在每次更新参数时使用m’个样本, m’可能远小于m。
3、卷积池化全连接,激活、Dropout BNL
CNN由输入层、卷积层、激活函数、池化层、全连接层组成。
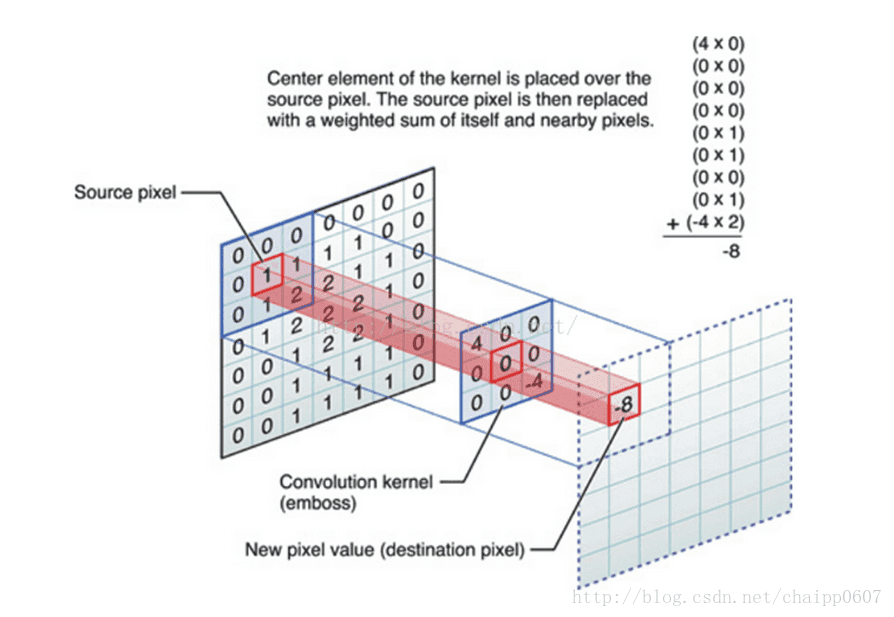
卷积层
特征提取,滑窗
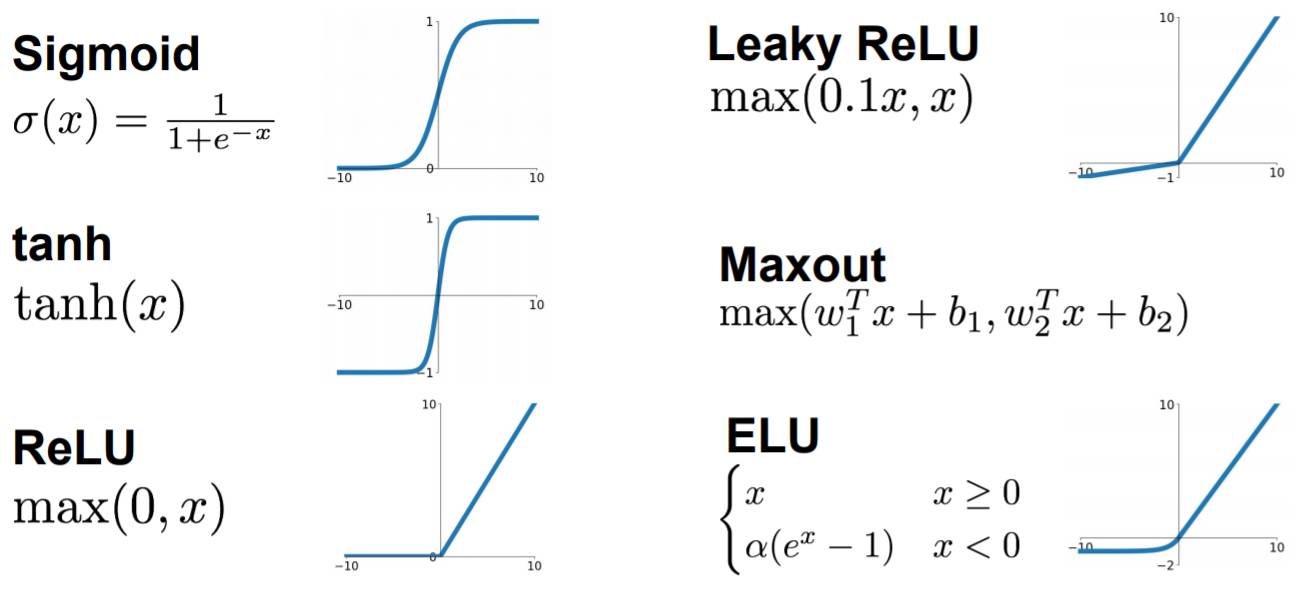
激活函数:
池化层
提取局部均值与最大值,有average pooling 与max pooling

全连接层
把卷積輸出的二維特徵圖轉換成一維的向量,在整个卷积神经网络中起到“分类器”的作用,把特征representation整合到一起,输出为一个值。全连接层之前的作用是提取特征,全连接层的作用是分类。
怎么样把3x3x5的输出,转换成1x4096的形式?靠的就是全连接层
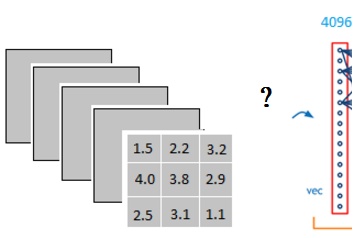
可以理解为在中间做了一个卷积
用一个3x3x5的filter 去卷积激活函数的输出,得到的结果就是一个fully connected layer 的一个神经元的输出,这个输出就是一个值

全连接层的操作把分布式特征representation映射到样本标记空间(把特征representation整合到一起,输出为一个值),空间结构特性被忽略了,所以全连接层不适合用于在方位上找Pattern的任务,比如segmentation。
全连接层之前的作用是提取特征, 全理解层的作用是分类!
参考:CNN 入门讲解:什么是全连接层(Fully Connected Layer)?
激活函数
Dropout
适当地对神经元进行概率为p的丢弃,避免在深层神经网络下较少训练数据的过拟合现象。
过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
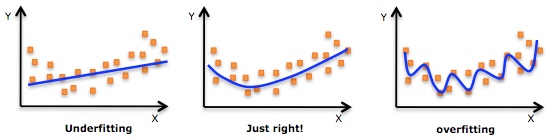
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
Dropout被大量利用于全连接网络,而且一般认为设置为0.5或者0.3,而在卷积网络隐藏层中由于卷积自身的稀疏化以及稀疏化的ReLu函数的大量使用等原因,Dropout策略在卷积网络隐藏层中使用较少。总体而言,Dropout是一个超参,需要根据具体的网络、具体的应用领域进行尝试。
BatchNormalization(批归一化,标准化)
随着网络的深度增加,每层特征值分布会逐渐的向激活函数的输出区间的上下两端(激活函数饱和区间)靠近,这样继续下去就会导致梯度消失。BN就是通过方法将该层特征值分布重新拉回标准正态分布,特征值将落在激活函数对于输入较为敏感的区间,输入的小变化可导致损失函数较大的变化,使得梯度变大,避免梯度消失,同时也可加快收敛。
数据经过 \[ \sigma(WX+b) \]
这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。
通常BN网络层用在卷积层后,用于重新调整数据分布的归一化。
为什么要归一化?
- 为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
- 为了程序运行时收敛加快。
- 同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
- 避免神经元饱和。啥意思?就是当神经元的激活在接近 0 或者 1 时会饱和,在这些区域,梯度几乎为 0,这样,在反向传播过程中,局部梯度就会接近 0,这会有效地“杀死”梯度。
- 保证输出数据中数值小的不被吞食。
在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
BN比较适用的场景是:每个mini-batch比较大,数据分布比较接近。在进行训练之前,要做好充分的shuffle,否则效果会差很多。另外,由于BN需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态的网络结构和RNN网络。
4、滑动平均模型
5、感知野
感受野,用来表示网络内部的不同位置的神经元对原图像的感受范围的大小。
神经元感受野的值越大表示其能接触到的原始图像范围就越大,也意味着他可能蕴含更为全局、语义层次更高的特征;而值越小则表示其所包含的特征越趋向于局部和细节。因此感受野的值可以大致用来判断每一层的抽象层次。

在Conv1中的每一个单元所能看到的原始图像范围是3*3,而由于Conv2的每个单元都是由2×2范围的Conv1构成,因此回溯到原始图像,其实是能够看到5×5的原始图像范围的。因此我们说Conv1的感受野是3,Conv2的感受野是5. 输入图像的每个单元的感受野被定义为1
参考:深度神经网络中的感受野(Receptive Field)
6、SVM
在机器学习中,支持向量机(英语:support vector machine,常简称为SVM,又名支持向量网络)是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。
优化目标为:最大化分类间隔。通俗地来讲,区分两堆点用线区分,区分两堆线要用面,总是要使用高一维度的数据来做分类器的判定原则。
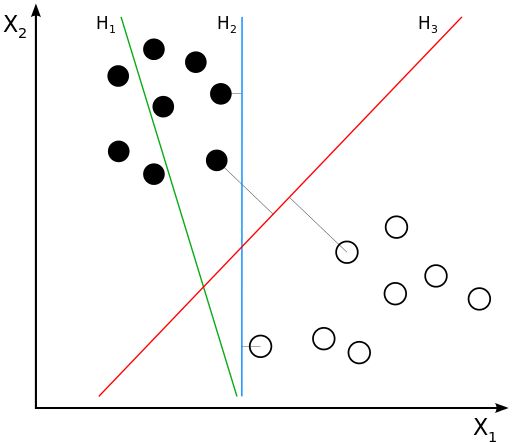
类别
- 线性可分SVM
当训练数据线性可分时,通过硬间隔(hard margin,什么是硬、软间隔下面会讲)最大化可以学习得到一个线性分类器,即硬间隔SVM,如上图的的H3。
什么是支持向量? 在线性可分的情况下,训练数据集的样本点中与分离超平面距离最近的数据点称为支持向量(support vector),也即所有在图中虚线上的点。如下图所示:

在决定最佳超平面时只有支持向量起作用,而其他数据点并不起作用。如果移动非支持向量,甚至删除非支持向量都不会对最优超平面产生任何影响。也即支持向量对模型起着决定性的作用,这也是“支持向量机”名称的由来。
- 线性SVM
当训练数据不能线性可分但是可以近似线性可分时(不能完全分割,有部分数据错误分类),通过软间隔(soft margin)最大化也可以学习到一个线性分类器,即软间隔SVM。
- 非线性SVM
当训练数据线性不可分时,通过使用核技巧(kernel trick, 空间转化)和软间隔最大化,可以学习到一个非线性SVM。
总结(SVM)
支持向量机的优点是:
- 1、由于SVM是一个凸优化问题,所以求得的解一定是全局最优而不是局部最优。
- 2、不仅适用于线性线性问题还适用于非线性问题(用核技巧)。
- 3、拥有高维样本空间的数据也能用SVM,这是因为数据集的复杂度只取决于支持向量而不是数据集的维度,这在某种意义上避免了“维数灾难”。
- 4、理论基础比较完善(例如神经网络就更像一个黑盒子)。
- 5、支持向量机的缺点是:
二次规划问题求解将涉及m阶矩阵的计算(m为样本的个数), 因此SVM不适用于超大数据集。(SMO算法可以缓解这个问题) 只适用于二分类问题。(SVM的推广SVR也适用于回归问题;可以通过多个SVM的组合来解决多分类问题)
7、损失函数计算和优化方法
各类损失函数
| loss 方法 | 具体计算 | |
|---|---|---|
| Binary Crossentropy | 使用交叉熵损失计算真实标签与预测标签 | |
各类优化方法
8、Select Search
基本步骤: 基于图的图像分割方法将图像分割成很多小块 使用贪心策略,计算每两个相邻区域的相似度 合并最相似的两块,直到最终剩下一块完整的图片 保存每次产生的图像快包括合并的图像
HOG
9、training set、epoch与batch区别
以CIFAR10数据集举例。CIFAR10数据集合有50000张图片,training set训练集为5w。Epoch为要把训练集轮几遍的意思,若epoch==10,则会让网络轮10遍训练集。Batch是针对每个Epoch而言,若设置Batch Size==100,则每个epoch中有(5w/100=)500个batch,会更新500次权重。
归纳:5w张训练图像,先100张图像一份,分成500份,每训练1份(100张)图像,更新一次参数,直至训练了500次,完成了一个epoch的训练。
n-1、
1 | x = tf.placeholder("float", [None, 784]) |
x不是一个特定的值,而是一个占位符placeholder,我们在TensorFlow运行计算时输入这个值。我们希望能够输入任意数量的MNIST图像,每一张图展平成784维的向量。我们用2维的浮点数张量来表示这些图,这个张量的形状是[None,784 ]。(这里的None表示此张量的第一个维度可以是任何长度的。)
需要学习的参数值使用tf.variable
1 | W = tf.Variable(tf.zeros([784,10])) |
第四章摘要 神经网络工具箱
我们赋予tf.Variable不同的初值来创建不同的Variable:在这里,我们都用全为零的张量来初始化W和b。因为我们要学习W和b的值,它们的初值可以随意设置。
nn中还有一个很常用的模块:nn.functional,nn中的大多数layer,在functional中都有一个与之相对应的函数。nn.functional中的函数和nn.Module的主要区别在于,用nn.Module实现的layers是一个特殊的类,都是由class layer(nn.Module)定义,会自动提取可学习的参数。而nn.functional中的函数更像是纯函数,由def function(input)定义。
如果模型有可学习的参数,最好用nn.Module,如激活函数(ReLU、sigmoid、tanh),池化(MaxPool)等层由于没有可学习参数,则可以使用对应的functional函数代替,而对于卷积、全连接等具有可学习参数的网络建议使用nn.Module。 其中Sequential是一个特殊的module,它包含几个子Module,前向传播时会将输入一层接一层的传递下去。
ResNet
特征描述子应对目标识别,老旧的特征识别算子 SIFT HOG
方向梯度直方图(Histogram of Oriented Gradient, HOG)HOG+SVM进行行人检测
HOG特征提取:
1)灰度化(将图像看做一个x,y,z(灰度)的三维图像);
2)采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
4)将图像划分成小cells(例如6*6像素/cell);
5)统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor;
6)将每几个cell组成一个block(例如3*3个cell/block),一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
7)将图像image内的所有block的HOG特征descriptor串联起来就可以得到该image(你要检测的目标)的HOG特征descriptor了。这个就是最终的可供分类使用的特征向量了。
fine-tune Fine-tune时可以选择fine-tune全部层或部分层。通常,前面的层提取的是图像的通用特征(generic features)(例如边缘检测,色彩检测),这些特征对许多任务都有用。后面的层提取的是与特定类别有关的特征,因此fine-tune时常常只需要Fine-tuning后面的层。
n、计算图
在PyTorch中计算图的特点可总结如下:
autograd根据用户对variable的操作构建其计算图。对变量的操作抽象为
Function。对于那些不是任何函数(Function)的输出,由用户创建的节点称为叶子节点,叶子节点的
grad_fn为None。叶子节点中需要求导的variable,具有AccumulateGrad标识,因其梯度是累加的。variable默认是不需要求导的,即
requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。variable的
volatile属性默认为False,如果某一个variable的volatile属性被设为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad高。多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需指定
retain_graph=True来保存这些缓存。非叶子节点的梯度计算完之后即被清空,可以使用
autograd.grad或hook技术获取非叶子节点的值。variable的grad与data形状一致,应避免直接修改variable.data,因为对data的直接操作无法利用autograd进行反向传播
反向传播函数
backward的参数grad_variables可以看成链式求导的中间结果,如果是标量,可以省略,默认为1PyTorch采用动态图设计,可以很方便地查看中间层的输出,动态的设计计算图结构。
三、常见的模型结构
一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
1、AlexNet
AlexNet的网络结构图:
原始的网络采用上下两个GPU并行运算,在特定的二、四、五层进行数据交互。
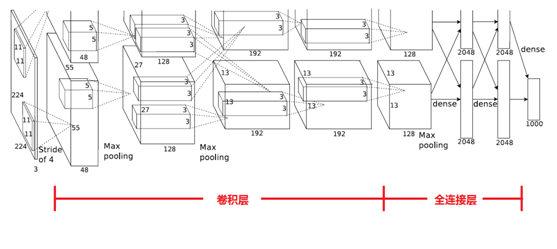

各层之间的数据传递:
| input vector size | layer | cal |
|---|---|---|
| 227×227×3 | conv1: 11×11×3, stride:4, kernels:96 | (227-11)/4+1=55 |
| 55×55×96 | pool: 3×3, stride:2 | (55-3)/2+1=27 |
| 27×27×96 | conv2: 5×5×96, padding:4, kernels:256 | (27-5+2×2)/2+1=27 |
| 27×27×256 | pool: 3×3, stride:2 | (27-3)/2+1=13 |
| 13×13×256 | conv3: 3×3×256, padding:1, kernels:384 | (13-3+2×1)/2+1=13 |
| 13×13×384 | conv4: 3×3×384, padding:1, kernels:384 | (13-3+2×1)/2+1=13 |
| 13×13×384 | conv5: 3×3×384, padding:1, kernels:256 | (13-3+2×1)/2+1=13 |
| 13×13×256 | pool: 3×3, stride:2 | (13-3)/2+1=6 |
| 6×6×256 | FC1: 6×6×256×4096 | pass |
| 1×4096 | FC2: 4096×4096 | pass |
| 1×4096 | FC2: 4096×1000 | finally output: 1×1000 |
AlexNet网络结构共有8层,前面5层是卷积层,后面3层是全连接层,最后一个全连接层的输出传递给一个1000路的softmax层,对应1000个类标签的分布。
由于AlexNet采用了两个GPU进行训练,因此,该网络结构图由上下两部分组成,一个GPU运行图上方的层,另一个运行图下方的层,两个GPU只在特定的层通信。例如第二、四、五层卷积层的核只和同一个GPU上的前一层的核特征图相连,第三层卷积层和第二层所有的核特征图相连接,全连接层中的神经元和前一层中的所有神经元相连接。
参考:
CNN 入门讲解:什么是全连接层(Fully Connected Layer)?
2、VGG
VGG是Oxford的Visual Geometry Group的组提出的,主要有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
结构

原理
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 3x(9xC^2) ,如果直接使用7x7卷积核,其参数总量为 49xC^2 ,这里 C 指的是输入和输出的通道数。很明显,27xC2小于49xC2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
为什么使用2个3x3卷积核可以来代替5*5卷积核:
5x5卷积看做一个小的全连接网络在5x5区域滑动,我们可以先用一个3x3的卷积滤波器卷积,然后再用一个全连接层连接这个3x3卷积输出,这个全连接层我们也可以看做一个3x3卷积层。这样我们就可以用两个3x3卷积级联(叠加)起来代替一个5x5卷积。

VGG优缺点
优点:
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。 几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好: 验证了通过不断加深网络结构可以提升性能。
缺点:
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
3、R-CNN
迁移学习
所谓的有监督预训练也可以把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。然后当你遇到新的项目任务时:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练,让它输出性别。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。
对于目标检测问题: 图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,这篇论文采用了迁移学习的思想: 先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行网络图片分类训练。这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段CNN模型的输出是1000个神经元(当然也直接可以采用Alexnet训练好的模型参数)。
基于Alexnet,设计fine-tuning CNN模型,softmax分类输出层为21个神经元。
训练
采用迁移学习,提取 ILSVRC(ImageNet Large Scale Visual Recognition Competition)2012 的模型与权重,在VOC(Visual Object Classes)上进行fine-tune(微调)。 当前训练学习的是识别类型的能力,不是预测bbox的能力,
R-CNN 将候选区域与 GroundTrue 中的 box 标签相比较,如果 IoU > 0.5,说明两个对象重叠的位置比较多,于是就可以认为这个候选区域是 Positive,否则就是 Negetive。
训练策略是:采用 SGD 训练,初始学习率为 0.001,mini-batch 大小为 128。
R-CNN的三个步骤 1、候选区域生成:给定一张输入图片,从图片中提取 2000 个类别独立的候选区域(采用Selective Search 方法)。 2、特征提取:对于每个区域利用 CNN 抽取一个固定长度的特征向量。 3、类别判断:再对每个区域利用 SVM 进行目标分类。 4、位置精修:使用回归器精细修正候选框位置bbox
- 候选区域生成
输入:image,输出:200个227*227的bbox
生产类别独立的候选区域,这些候选区域其中包含了 R-CNN 最终定位的结果,使用selective search算法,生成候选区域。 select search 使用felzenszwalb segmentation 生成。 搜出的候选框是矩形的,而且是大小各不相同,需要缩放处理成相同尺寸丢进CNN(输入227*227)。经过最后的试验,论文作者发现先padding=16扩充后,然后再采用“各向异性缩放”到固定大小精度最高。
- CNN特征提取
输入:image中的bbox image,输出:固定长度的特征向量
a、网络结构设计 选用Alexnet,Alexnet特征提取部分包含了5个卷积层、2个全连接层,在Alexnet中p5层神经元个数为9216、f6、f7的神经元个数都是4096,通过这个网络训练完毕后,最后提取特征每个输入候选框图片都能得到一个4096维的特征向量。

b、网络有监督预训练分类阶段(图片数据库:ImageNet ILSVC) 参数初始化部分:物体检测的一个难点在于,物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法,那么目前的训练数据量是远远不够的。这种情况下,最好的是采用某些方法,把参数初始化了,然后在进行有监督的参数微调,这里文献采用的是有监督的预训练。所以paper在设计网络结构的时候,是直接用Alexnet的网络,然后连参数也是直接采用它的参数,作为初始的参数值,然后再fine-tuning训练。网络优化求解时采用随机梯度下降法,学习率大小为0.001;
C、fine-tuning检测阶段(图片数据库:PASCAL VOC) 我们接着采用 selective search 搜索出来的候选框 (PASCAL VOC 数据库中的图片) 继续对上面预训练的CNN模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景) (20 + 1bg = 21),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。开始的时候,SGD学习率选择0.001,在每次训练的时候,我们batch size大小选择128,其中32个正样本、96个负样本。
正负样本定义: 一张照片我们得到了2000个候选框。然而人工标注的数据一张图片中就只标注了正确的bounding box,我们搜索出来的2000个矩形框也不可能会出现一个与人工标注完全匹配的候选框。因此在CNN阶段我们需要用IOU为2000个bounding box打标签。如果用selective search挑选出来的候选框与物体的人工标注矩形框(PASCAL VOC的图片都有人工标注)的重叠区域IoU大于0.5,那么我们就把这个候选框标注成物体类别(正样本),否则我们就把它当做背景类别(负样本)。
CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
- SVM分类器
输入:CNN产生的特征向量,输出:类别及其分数?
将每个提议区域的特征连同其标注的类别作为⼀个样本,训练多个⽀持向量机对⽬标分类。其中每个⽀持向量机⽤来判断样本是否属于某⼀个类别。
一旦CNN f7层特征被提取出来,那么我们将为每个物体类训练一个svm分类器。当我们用CNN提取2000个候选框,可以得到20004096这样的特征向量矩阵,然后我们只需要把这样的一个矩阵与svm权值矩阵4096N点乘(N为分类类别数目,因为我们训练的N个svm,每个svm包含了4096个权值w)(对提取的特征向量进行打分,得到测试图片中对于所有region proposals的对于这一类的分数)就可以得到结果了。
- 位置精修
将每个提议区域的特征连同其标注的边界框作为⼀个样本,训练线性回归模型来预测真实边界框。
测试阶段的目标检测
可视化
思路是挑选一个特征出来,把它直接当成一个物体分类器,然后计算它们处理不同的候选区域时,activation的值,这个值代表了特征对这块区域的响应情况,然后将activation作为分数排名,取前几位,然后显示这些候选区域,自然也可以清楚明白,这个feature大概是什么。
R-CNN 作者将 pool5 作为可视化对象,它的 feature map 是 6x6x255 的规格,可以理解为有 256 个小方块,每个方块对应一个特征。
R-CNN总结
采用 AlexNet 采用 Selective Search 技术生成 Region Proposal 在 ImageNet 上先进行预训练,然后利用成熟的权重参数在 PASCAL VOC 数据集上进行 fine-tune 用 CNN 抽取特征,然后用一系列的的 SVM 做类别预测。 的 bbox 位置回归基于 DPM 的灵感,自己训练了一个线性回归模型。 的语义分割采用 CPMC 生成 Region
此paper采用的方法是:首先输入一张图片,我们先定位出2000个物体候选框,然后采用CNN提取每个候选框中图片的特征向量,特征向量的维度为4096维,接着采用svm算法对各个候选框中的物体进行分类识别
存在问题
R-CNN虽然不再像传统方法那样穷举,但R-CNN流程的第一步中对原始图片通过Selective Search提取的候选框region proposal多达2000个左右,而这2000个候选框每个框都需要进行CNN提特征+SVM分类,计算量很大,导致R-CNN检测速度很慢,一张图都需要47s。 为了提速,这2000个region proposal不都是图像的一部分吗,那么我们完全可以对图像提一次卷积层特征,然后只需要将region proposal在原图的位置映射到卷积层特征图上,这样对于一张图像我们只需要提一次卷积层特征,然后将每个region proposal的卷积层特征输入到全连接层做后续操作。
但现在的问题是每个region proposal的尺度不一样,而全连接层输入必须是固定的长度,所以直接这样输入全连接层肯定是不行的。SPP Net恰好可以解决这个问题。
SPP:Spatial Pyramid Pooling(空间金字塔池化) SPP Net的作者Kaiming He等人逆向思考,既然由于全连接FC层的存在,普通的CNN需要通过固定输入图片的大小来使得全连接层的输入固定。那借鉴卷积层可以适应任何尺寸,为何不能在卷积层的最后加入某种结构,使得后面全连接层得到的输入变成固定的呢?
简言之,CNN原本只能固定输入、固定输出,CNN加上SSP之后,便能任意输入、固定输出。
SPP 空间金字塔池化
代码实现
4、fast R-CNN
Fast R-CNN就是在R-CNN的基础上采纳了SPP Net方法,对R-CNN作了改进,使得性能进一步提高。
tips:边框回归
之前R-CNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression,而在Fast R-CNN中,作者巧妙的把bbox regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征,并相互促进。
R-CNN有一些相当大的缺点(把这些缺点都改掉了,就成了Fast R-CNN)。 大缺点:由于每一个候选框都要独自经过CNN,这使得花费的时间非常多。 解决:共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征
原来的方法:许多候选框(比如两千个)-->CNN-->得到每个候选框的特征-->分类+回归 现在的方法:一张完整图片-->CNN-->得到每张候选框的特征-->分类+回归
所以容易看见,Fast R-CNN相对于R-CNN的提速原因就在于:不过不像R-CNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。
5、faster R-CNN
参考与引用:

相比较于fast rcnn,加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。一个神经网络层所提取到的feature既用于bbox的选择,也用于最后的object detection。
PRN(region proposal network)

上图(rpn_flow)展示了RPN网络的具体结构。
可以看到RPN网络实际分为2条主线
上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。
而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能。
其实RPN最终就是在原图尺度上,设置了密密麻麻的候选Anchor。然后用cnn去判断哪些Anchor是里面有目标的positive anchor,哪些是没目标的negative anchor。所以,仅仅是个二分类而已!
- anchors
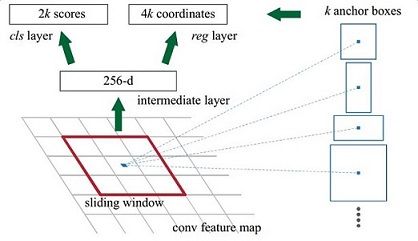
每个feature map的最小单位对应一个anchors,固定面积根据长宽比例生成9个对应的候选框。
- bounding box regression
寻找一种关系,使得输入原始的anchor A经过映射得到一个跟真实窗口G更接近的回归窗口G',用线性回归来建模对窗口进行微调。对于训练bouding box regression网络回归分支,输入是cnn feature Φ,监督信号是Anchor与GT的差距,即训练目标是:输入 Φ的情况下使网络输出与监督信号尽可能接近。那么当bouding box regression工作时,再输入Φ时,回归网络分支的输出就是每个Anchor的平移量和变换尺度,显然即可用来修正Anchor位置了。
回到图(faster_rcnn),VGG输出 5038512 的特征,对应设置 5038k 个anchors,而RPN输出:
1.大小为50382k 的positive/negative softmax分类特征矩阵
2.大小为50384k 的regression坐标回归特征矩阵 恰好满足RPN完成positive/negative分类+bounding box regression坐标回归.
- proposal layer
Proposal Layer负责综合所有 [dx(A), dy(A), dw(A), dh(A)] 变换量和positive anchors,计算出精准的proposal,送入后续RoI Pooling Layer。
Proposal Layer有3个输入:positive和negative anchors分类器结果rpn_cls_prob_reshape,对应的bbox reg的(e.g. 300)结果作为proposal输出
Proposal Layer forward(caffe layer的前传函数)按照以下顺序依次处理:
生成anchors,利用[dx(A), dy(A), dw(A), dh(A)]对所有的anchors做bbox regression回归(这里的anchors生成和训练时完全一致)
按照输入的positive softmax scores由大到小排序anchors,提取前pre_nms_topN(e.g. 6000)个anchors,即提取修正位置后的positive anchors
限定超出图像边界的positive anchors为图像边界,防止后续roi pooling时proposal超出图像边界
剔除尺寸非常小的positive anchors
对剩余的positive anchors进行NMS(nonmaximum suppression)
之后输出proposal=[x1, y1, x2, y2],注意,由于在第三步中将anchors映射回原图判断是否超出边界,所以这里输出的proposal是对应MxN输入图像尺度的,这点在后续网络中有用。严格意义上的检测应该到此就结束了,后续部分应该属于识别了。
RPN网络结构就介绍到这里,总结起来就是: 生成anchors -> softmax分类器提取positvie anchors -> bbox reg回归positive anchors -> Proposal Layer生成proposals
POI Pulling

该层的两个输入:
- 原始的feature maps
- RPN输出的proposal boxes(大小各不相同)
处理后,即使大小不同的proposal输出结果都是 pooled_w*polled_h 固定大小,实现了固定长度输出。
Classification

Classification部分利用已经获得的proposal feature maps,通过full connect层与softmax计算每个proposal具体属于那个类别(如人,车,电视等),输出cls_prob概率向量;同时再次利用bounding box regression获得每个proposal的位置偏移量bbox_pred,用于回归更加精确的目标检测框
Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。那我们能不能找出一个更加高效的方法来求出这些候选框呢?
6、mask R-CNN
7、YOLOv3
key words:端到端,darknet-53,参差网络、BN+LeakyRelu
yolov3没有使用polling和FC,v2中的池化方法在v3中使用增大步长的卷积核实现,在backbone中,会有5次增大步长的卷积操作这也是从输入416x416=>13*13的原因(下降了2^5)。
所使用的特征层是32的倍数
借鉴FPN(feature pyramid networks),输出了三个feature map,多尺度进行目标检测,三个feature map的深度都是255,边长比52:26:13。每次对应的感受野不同,32倍降采样的感受野最大。
当输入为416x416时,实际总共有(52x52+26x26+13x13)x3=10647个proposal box。
对于coco数据集合,80个类别,每个网格预测三个box,每个box有(x,y,w,h,confidence)五个参数,再加上80个类别的概率,所以每个feature map的深度=3*(5+80)=255。
张量拼接,与后面网络层的上采样结果进行一个拼接后的处理结果作为feature map的输出。
details:
bbox的预测:
直接运用逻辑回归预测bbox中心点相对于网络单元左上角的相对位置。给定9个在数据集上聚类的参数,分别是宽和高。设置阈值对模板框进行筛选。 V3只会在一个模板框上面进行预测,(如何在9个中选择1个???逻辑回归实现,用曲线对模板框相对于目标物体的分数映射关系),每个feature map使用9//3个模板框。
loss function:
x,y,w,h使用the mean squared error (squared L2 norm)计算 class,confidence使用Binary Cross Entropy二值交叉熵 总loss将以上相加得到。
训练分析:


yolov3 网络结构比较大,且输入为416x416,由于显存的限制,训练的时候batch size只能为1。
从上图可以看出,在前500个batch,loss下降的比较明显,而从200~10k batch的时候,l在所以几乎oss几乎没什么变化,一直在10-20徘徊。
实验在一个epoch后就不怎么收敛了,需要显存够大的情况下训练效果才比较明显。(to do)
yolov3-tiny batch size能够设置到16。
训练日志
yolo-tiny在epoch5-50的迭代中,训练loss一直是3~4左右。
总结
最后总结一下各大算法的步骤: RCNN 1.在图像中确定约1000-2000个候选框 (使用选择性搜索Selective Search) 2.每个候选框内图像块缩放至相同大小,并输入到CNN内进行特征提取 3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类 4.对于属于某一类别的候选框,用回归器进一步调整其位置
Fast R-CNN 1.在图像中确定约1000-2000个候选框 (使用选择性搜索Selective Search) 2.对整张图片输进CNN,得到feature map 3.找到每个候选框在feature map上的映射patch,将此patch作为每个候选框的卷积特征输入到SPP layer和之后的层 4.对候选框中提取出的特征,使用分类器判别是否属于一个特定类 5.对于属于某一类别的候选框,用回归器进一步调整其位置
Faster R-CNN 1.对整张图片输进CNN,得到feature map 2.卷积特征输入到RPN,得到候选框的特征信息 3.对候选框中提取出的特征,使用分类器判别是否属于一个特定类 4.对于属于某一类别的候选框,用回归器进一步调整其位置
R-CNN(Selective Search + CNN + SVM) SPP-net(ROI Pooling) Fast R-CNN(Selective Search + CNN + ROI) Faster R-CNN(RPN + CNN + ROI Pooling)
Mask RCNN 1.
YOLOV3 1.
参考与引用
检测评价函数 intersection-over-union ( IOU )
四、数据集
The PASCAL Visual Object Classes Homepage
五、疑问
- 1、TensorFlow GPU:ran out of memory trying to allocate 1.14GiB
遇到类似问题,应该减小BatchSize。cifar10数据集train image size为[32,32],在将模型切换到官方VGG16版本的时候,需要将第一层数据缩放至[224,224],所以,先前的batch size就太大了,gpu一次吃不了一个batch的数据,导致警告,甚至无法训练,就需要减小batch size的尺寸。
六、所有参考来源
参考:深度神经网络中的感受野(Receptive Field)
一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
 wechat
wechat alipay
alipay