
c++并行使用手册
opencv并行
使用cv::parallel_for_函数对目标函数进行并行加速
官方函数原型
1 | inline void parallel_for_(const Range& range, std::function<void(const Range&)> functor, double nstripes=-1.) |
使用案例:求取0-1000的和与最大值
1 | std::atomic<int> _nSumValue = 0; |
上述代码中,存在2个原子变量_nSumValue和_nMax,是为了避免出现多线程竞争资源时,变量同时累加导致结果不一致。
若为原始int型变量,观察多次运行结果,发现每次运行的值不一致!如下
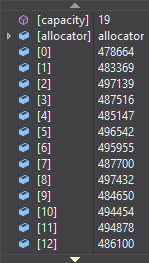
为了避免此种现象的发生
- 变量改为原子型
- 增加互斥锁
openMP
vs项目配置

验证openMP是否开启成功:
1 |
|
openMP指令
- 考虑一个简单的例子,两个线程都试图同时更新变量x:
| THREAD 1: | THREAD 2: |
|---|---|
| update(x) { x = x + 1 } x=0 update(x) print(x) |
update(x) { x = x + 1 } x=0 update(x) print(x) |
- 一种可能的执行顺序:
- 线程1初始化
x为0并调用 - 线程1将
x加1,x现在等于1 - 线程2初始化
x为0并调用update(x),x现在等于0 - 线程1输出
x,它等于0而不是1 - 线程2将
x加1,x现在等于1 - 线程2打印
x为1
- 线程1初始化
- 为了避免这种情况,必须在两个线程之间同步
x的更新,以确保产生正确的结果。 - OpenMP 提供了各种同步结构,这些构造控制每个线程相对于其他团队线程的执行方式。
master 指令
master指令指定了一个区域,该区域只由团队的主线程执行。团队中的所有其他线程都将跳过这部分代码。- 这个指令没有隐含的障碍(
implied barrier)。
1 |
|
- 进入或跳出一个
master代码块是非法的。
critical 指令
critical指令指定了一个只能由一个线程执行的代码区域。
1 |
|
注意事项
- 如果一个线程当前在一个
critical区域内执行,而另一个线程到达该critical区域并试图执行它,那么它将阻塞,直到第一个线程退出该critical区域。 - 可选的名称使多个不同的临界区域存在:
- 名称充当全局标识符。具有相同名称的不同临界区被视为相同的区域。
- 所有未命名的临界段均视为同一段。
限制条件
进入或跳出一个
critical代码块是非法的。Fortran only: The names of critical constructs are global entities of the program. If a name conflicts with any other entity, the behavior of the program is unspecified.
结构示例
- 团队中的所有线程都将尝试并行执行,但是由于
x的增加由critical结构包围,在任何时候只有一个线程能够读/增量/写x。
1 |
|
reduction 指令
用归约变量为每个线程创建一个私有的变量,用来存储自己归约的结果,并将最终结果写入全局共享变量,所以归约的代码不需要critical保护也不会发生冲突
使用案例分析
求取0-1000的和与最大值
1 |
|
reduction归约操作对指定变量_nSumValue求和操作,并将最终结果赋值给主线程中的sum变量。
在上面的程序当中我们使用了一个子句
reduction(+:_nSumValue) 在每个线程里面对变量
_nSumValue进行拷贝,然后在线程当中使用这个拷贝的变量,这样的话就不存在数据竞争了,因为每个线程使用的
_nSumValue是不一样的,在 reduction
当中还有一个加号➕,这个加号表示如何进行规约操作,所谓规约操作简单说来就是多个数据逐步进行操作最终得到一个不能够在进行规约的数据。
例如在上面的程序当中我们的规约操作是 + ,因此需要将线程 1 和线程 2 的数据进行 + 操作,即线程 1 的 _nSumValue加上 线程 2 的 _nSumValue值,然后将得到的结果赋值给全局变量 _nSumValue,这样的话我们最终得到的结果就是正确的。
如果有 4 个线程的话,那么就有 4 个线程本地的 _nSumValue(每个线程一个 _nSumValue)。那么规约(reduction)操作的结果等于:
(((_nSumValue1 + _nSumValue2) + _nSumValue3) +_nSumValue4)其中
_nSumValuei 表示第 i 个线程的得到的 _nSumValue。
参考引用
 wechat
wechat alipay
alipay